kafka数据存储机制
以三个broker为例
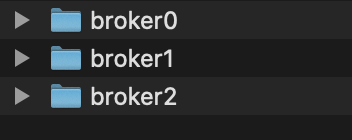
先看一下zookeeper中存储的broker信息
1 | ls /brokers/ids |
kafka数据存储机制之broker
创建一个三个分区两个副本的topic
1 | bin/kafka-topics.sh --zookeeper localhost:2181 --create --partitions 3 --replication-factor 2 --topic first |
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费
分区
可以看到当前zookeeper中存储的该topic下是有三个分区的
1 | ls /brokers/topics/first/partitions |
看一下每个分区的状态
分区0
1 | get /brokers/topics/first/partitions/0/state |
分区1
1 | get /brokers/topics/first/partitions/1/state |
分区2
1 | get /brokers/topics/first/partitions/2/state |
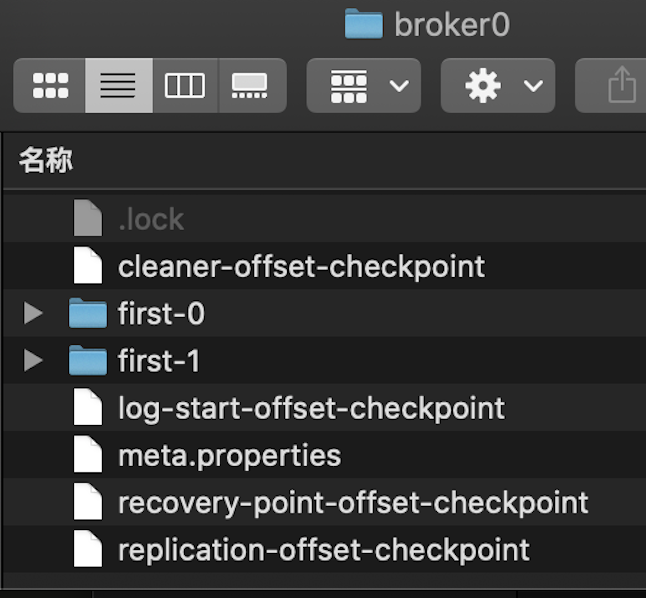
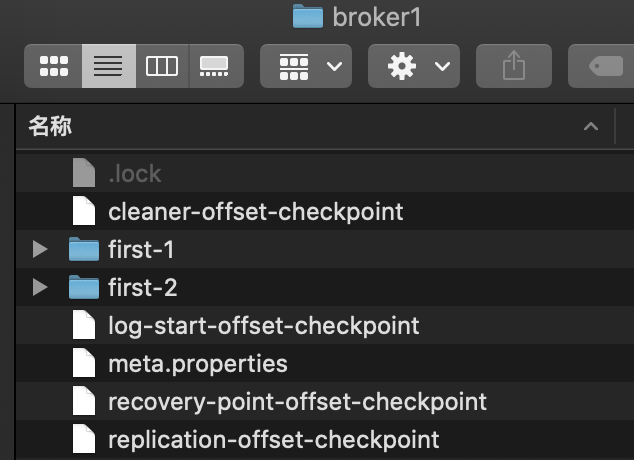
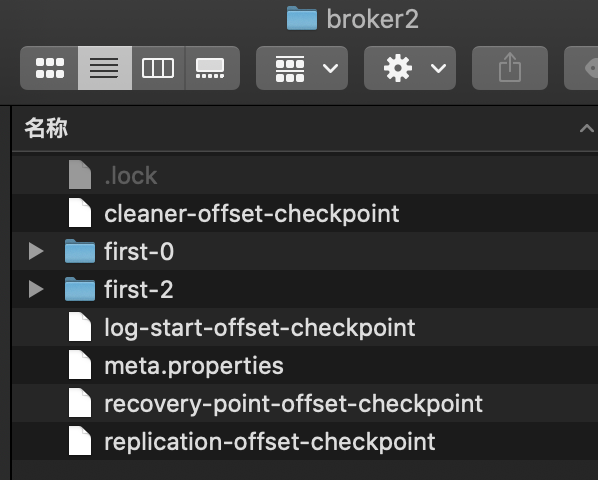
根据zookeeper中三个分区可以看到broker0中存储的是分区0和分区1的数据,其中分区0是leader;broker1中存储的是分区1和分区2的数据,其中分区1是leader;broker2中存储的是分区0和分区2的数据,其中分区2是leader
看一下是如何存储的
broker0
kafka数据存储机制之broker0存储
broker1
kafka数据存储机制之broker0存储
broker2
kafka数据存储机制之broker0存储
真正的数据存储在分区中的.log文件中,生产者的消息不断追加到log文件中,为了防止log文件过大导致数据定位效率低下,kafka采取了分片和索引的机制,每个partition下会有多个segment,每个segment对应两个文件.index文件和.log文件,文件名以该文件下的第一条消息的offset命名
kafka数据存储机制之分区数据
这种分段策略使用的是跳表的思想,如segment1文件名为1000.log,segment2文件名为3000.log,那么segment1中就存储了偏移量为1000-2999的消息,可以更快的查找数据,而且在进行清理数据的时候,也可以根据分段来更快的删除老数据。
.log文件中存储了大量的数据,.index文件中存储了大量的索引,索引文件中的元数据指向对应数据文件中message的物理偏移地址
.index文件中存储的内容是 offset(偏移量)和position(所处文件位置)
Index offset: 80, log offset: 78
Index offset: 64, log offset: 62
查看一下.log和.index文件中记录的大概是什么
.log文件内容
1 | bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/myself/kafka_2.12-2.1.0/datas/broker0/first-0/00000000000000000000.log --print-data-log |
记录了起始偏移量,每个偏移量所对应的位置
.index文件内容
1 | bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/myself/kafka_2.12-2.1.0/datas/broker0/springCloudBus-0/00000000000000000000.index --print-data-log |
index中使用的是稀疏索引,并不是所有的都记录,会每隔一个范围创建一个索引,使得既不占用太多的空间,还可以提供快速检索的能力
timeindex是用来根据时间检索的,可用于清除数据
所以在查询的时候是根据偏移量先通过二分法查询.index文件,找到数据所在的position之后,再去.log文件中顺序查找数据
v1.3.10