Lucene简介
lucene是apache旗下的一款高性能、可伸缩的开源的信息检索库,elasticsearch和sorl都是基于Lucene来实现的
概念
lucene中几个重要的概念
索引库Index
lucene中一个目录就是一个索引库,同一个文件夹下的所有文件构成一个索引库,一个索引是多个Document的集合
段Segment
Lucene索引可能由多个子索引组成,这些子索引称为段,每一段都是独立的索引,段与段之间是相互独立的。当添加一个新文档就会生成一个新的段,并且也会触发段文件合并,段文件中记录了索引中包含有多少个段,每个段包含有多少个文档
在Lucene中段是不可变的,只可读,不可写,此时对于不同的操作来说
- 增:有新数据需要创建索引时,由于段的不变性,会新建一个段来存储新增的数据
- 删:当删除数据时,由于段不可写,会在Lucene中新增一个.del文件,用来专门存储被删除的id。在查询时,被删除的数据还是可以被查到的,只有进行文档链表合并时,才会把删除的数据过滤掉(删除的数据在段合并的时候才会被真正移除)
- 改:修改操作其实就是删除+新增,先在.del文件中标记旧数据的删除,再在新段中添加一条更新后的数据
Lucene采用延迟写的方式,新增的数据会先写入内存,然后批量写到磁盘。若有一个段被写到磁盘,就会生成一个提交点,来记录所有提交后的段信息的文件。一个段一旦拥有了提交点,这个段就只可读不可写了,而段在内存中时,是只有写权限没有读权限的
延迟写可以减少磁盘写入次数,提升性能,降低磁盘压力
文档Document
文档(document),在lucene的定义中,文档是一系列域(field)的组合,而文档的域则代表一系列与文档相关的内容,与数据库表的记录的概念有点类似,一行记录所包含的字段对应的就是文档的域,举例来说,一个文档比如老师的个人信息,可能包括年龄、身高、性别、个人简介等等
域Field
域(field),索引的每个文档中都包含一个或者多个不同名称的域,每个域都包含了域的名称和域对应的值,并且,域还可以是不同的类型,如字符串、整型、浮点型等
- TextField 会把该字段的内容索引并词条化,但是不保存词向量
- StringField 只会对该字段的内容索引,但是并不词条化,也不保存词向量,字符串的值会被索引为一个单独的词Term
- IntPoint 索引值为int类型的字段
- LongPoint 索引值为long类型的字段
- FloatPoint 索引值为float类型的字段
- DoublePoint 索引值为double类型的字段
- SortedDocValuesField 存储值为内容文本的DocValue字段,适合索引字段值为文本内容并且需要按值进行排序的字段
- SortedSetDocValuesField 存储多值域的DocValues字段,适合索引字段值为文本内容且需要按值进行分组、聚合等操作的字段
- NumericDocValuesField 存储单个数字类型的DocValues字段
- SortedNumericDocValuesField 存储数值类型的有序数组列表的DocValues字段
- StoredField 适合索引只需要保存字段值不进行其他操作的字段
DocValues是Lucene在构建索引时额外建立的一个有序的基于document=>field/value的映射表,使得可以通过文档ID找到相应的字段(Elasticsearch中默认开启除需analyzed的字符串字段之外的所有字段的doc values,如果该字段不需要做任何排序的话可以关掉,减少资源消耗)
词项Term
词项(term),term是搜索的基本单元,与field对应,每个Filed的域值经过分词器处理之后得到的每一项称为Term,在两个不同field中的同一个字符被认为是不同的term,它包括了搜索的域的名称以及搜索的关键词,可以用它来查询指定域中包含特定内容的文档
词条(token)
词条(token)是指词项在字段文本中的一次出现,包括词项的文本、开始和结束的偏移以及词条类型
查询Query
查询(query),最基本的查询可能是一系列term的条件组合,称为TermQuery,但也有可能是短语查询(PhraseQuery)、前缀查询(PrefixQuery)、范围查询(包括TermRangeQuery、NumericRangeQuery等)等等
分词器Analyzer
分词器(analyzer),文档在被索引之前,需要经过分词器处理,以提取关键的语义单元,建立索引,并剔除无用的信息,如停止词等,以提高查询的准确性。中文分词与西文分词区别在于,中文对于词的提取更为复杂。
Analyzer内部主要通过TokenStream类来实现。Tokenizer和TokenFilter是TokenStream的重要的两个子类。
- Tokenizer 处理单个字符组成的字符流,读取Reader对象中的数据,处理完后转换为词汇单元
- TokenFilter 完成文本过滤器的功能
Lucene中提供的几个分词器
StopAnalyzer 停用词分词器
过滤词汇中的特定字符串和词汇,并且完成大写转小写的功能
StandardAnalyzer 标准分词器
根据空格和符号来完成分词,还可以完成数字、字母、email、ip以及中文字符的分析处理
WhitespaceAnalyzer 空格分词器
使用空格来作为词汇分割
SimpleAnalyzer 简单分词器
以非字母字符作为分隔符号
KeywordAnalyzer 关键词分词器
把整个输入作为一个单独词汇单元,方便特殊类型的文本进行索引和检索
常用的中文分词器包括一元分词、二元分词、词库分词等等。一元分词,即将给定的字符串以一个字为单位进行切割分词,这种分词方式较为明显的缺陷就是语义不准,如“上海”两个字被切割成“上”、“海”,但是包含“上海”、“海上”的文档都会命中。 二元分词比一元分词更符合中文的习惯,因为中文的大部分词汇都是两个字,但是问题依然存在。
词库分词就是使用词库中定义的词来对字符串进行切分,这样的好处是分词更为准确,但是效率较N元分词更低,且难以识别互联网世界中层出不穷的新兴词汇
索引构建过程
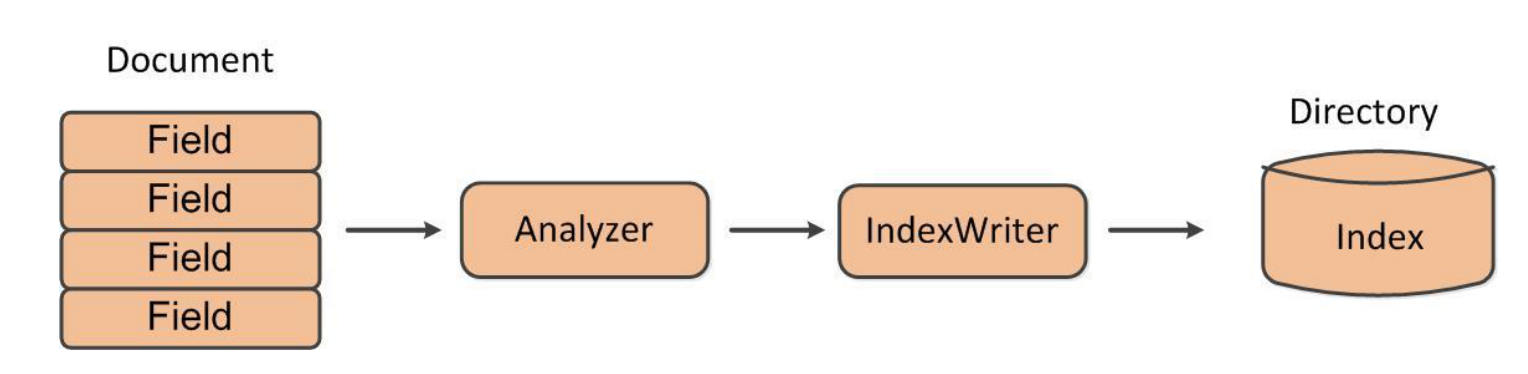
lucene索引的构建过程大致分为这样几个步骤,首先,通过指定的数据格式,将lucene的Document传递给分词器Analyzer进行分词,经过分词器分词之后,通过索引写入工具IndexWriter将索引写入到指定的目录
索引搜索过程
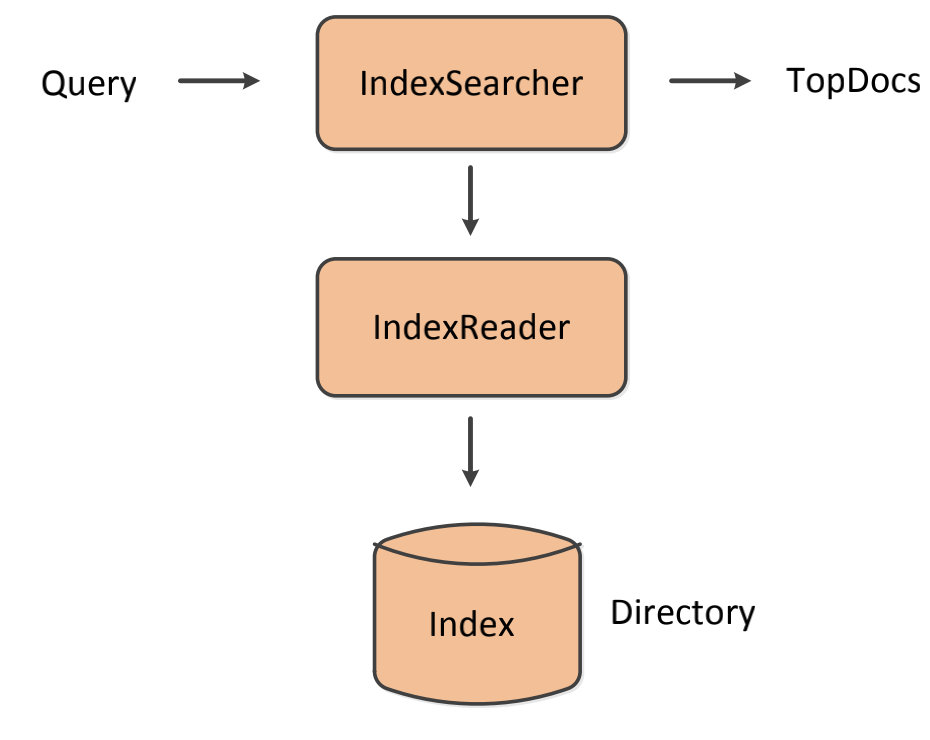
索引的查询,大概可以分为如下几个步骤,首先,构建查询的Query,通过IndexSearcher进行查询,得到命中的TopDocs,然后通过TopDocs的scoreDocs()方法,拿到ScoreDoc,通过ScoreDoc,得到对应的文档编号,IndexSearcher通过文档编号,使用IndexReader对指定目录下的索引内容进行读取,得到命中的文档返回