MAC地址
MAC地址是用于识别数据链路中互连的节点,标识同一个链路中不同计算机的的一种识别码
elasticsearch配置有两种配置方式,一种是静态配置,只能在配置文件中进行配置;一种是动态配置,可以通过_cluster/settings进行设置
本地网关是当所有集群重新启动时存储集群状态和分片数据的模块,属于静态配置
1 | "gateway": { |
进行执行IO操作就是向操作系统发起请求,写操作是让操作系统将缓冲区的数据写入磁盘,读操作是让操作系统将数据写入到缓冲区
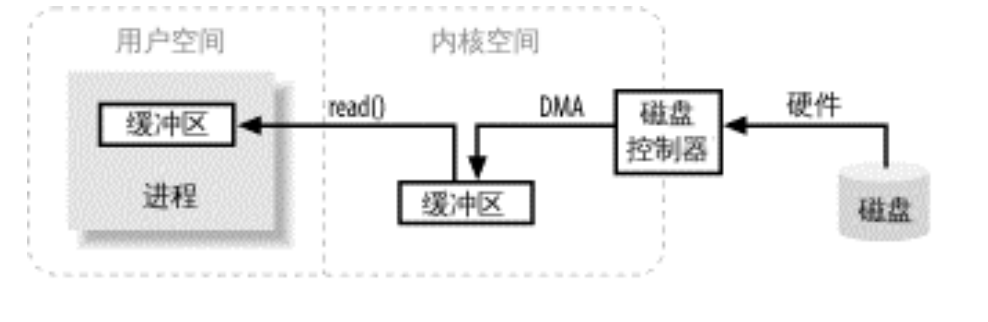
可以看到上图中的操作是读取磁盘的内容进行的操作,从磁盘读取数据需要通过DMA把数据写入到内核内存缓冲区,一旦磁盘控制器把缓冲区填满,内核就会把数据从内核空间的临时缓冲区拷贝到进程执行read()调用指定的缓冲区中
可能大家会感到意外,为什么还要有一个内核缓冲区和一个用户空间缓冲区呢,这一步从内核空间拷贝到用户空间是不是多余,这个问题首先硬件不能直接访问用户空间;其次,磁盘是基于块存储的,操作的是固定大小的数据块,而用户进程请求的可能是任意大小的或非对齐的数据块,内核需要在中间进行数据分解、再组合工作
聚合操作是一种基于搜索的数据汇总,可以对文档中的数据进行统计汇总、分组等,可分为以下几类
聚合操作的语法如下
1 | "aggregations" : { // 可缩写为aggs |
索引分析是在文档被发送到倒排索引之前,把一个文本块分析成一个个单独的词,为了后面的倒排索引做准备,然后标准化这些词为标准形式,提高它们的可搜索性,这些工作是分析器完成的,一个分析器是一个组合,用于将三个功能放在一起
elasticsearch有很多内置的分析器,也可以自定义分析器
调用顺序为Character Filters->Tokenizer->Token Filters