Tomcat类加载器
java本身的类加载器是双亲委派机制,而tomcat的应用场景是需要web应用类库隔离的,为了避免应用包之间相互影响,所以java原生的双亲委派是不可以在tomcat中使用了
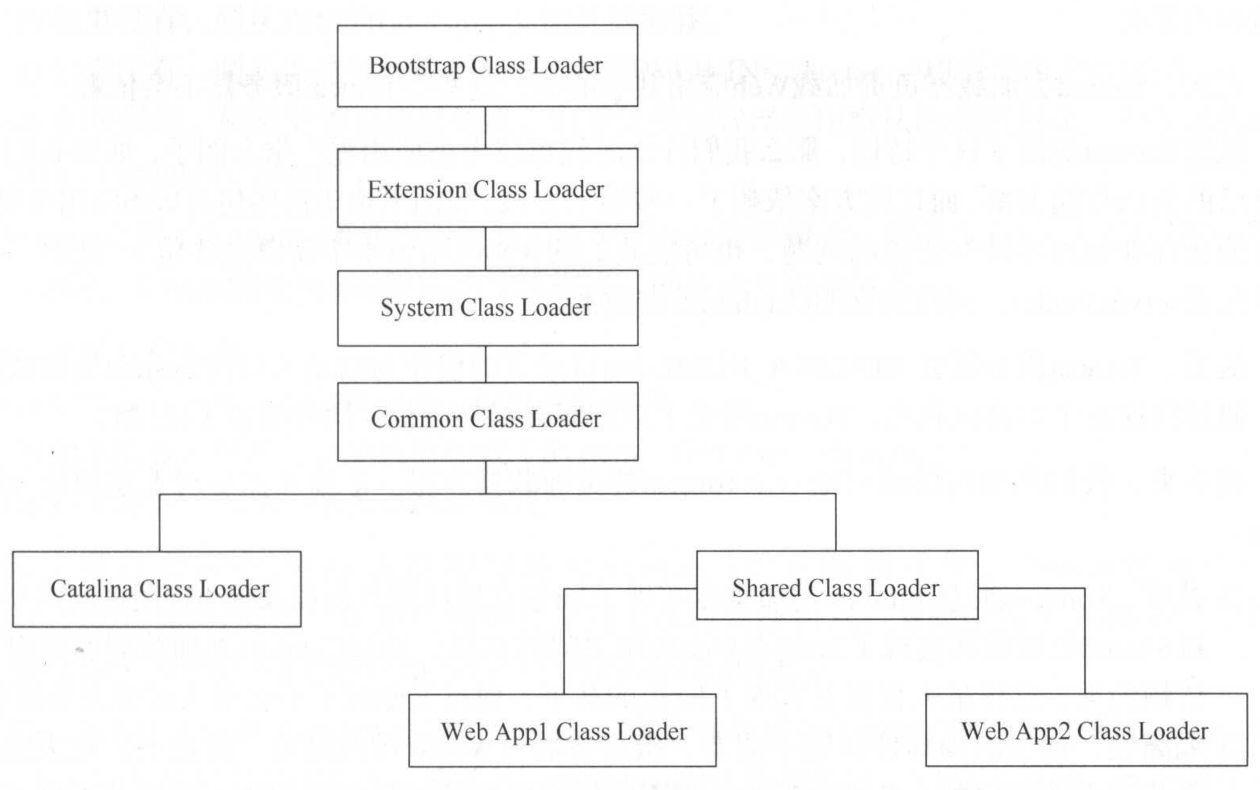
可以看到tomcat实现了自己的类加载器模型,在catalina.properties中进行配置
1 | ="${catalina.base}/lib","${catalina.base}/lib/*.jar","${catalina.home}/lib","${catalina.home}/lib/*.jar" |
只有指定了server.loader和shared.loader才会真正建立Catalina类加载器和Shared类加载器的实例