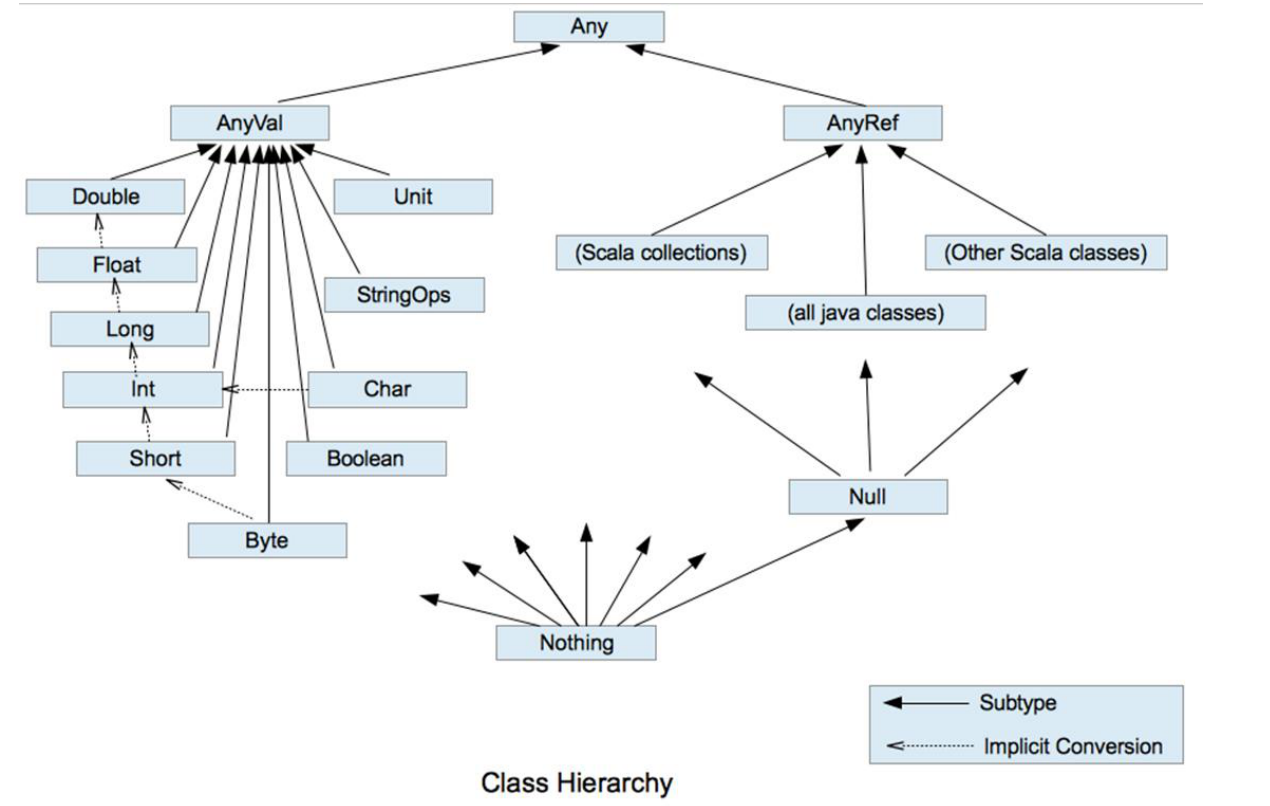
scala数据类型 发表于 2021-04-27 更新于 2021-05-11 分类于 scala 阅读次数: Valine: 本文字数: 526 阅读时长 ≈ 1 分钟 scala数据类型scala中的数据类型都是对象,没有像java那种的基本数据类型,不过scala数据类型分为两类,一类是AnyVal(值类型),一类为AnyRef(引用类型) 与java类似,scala有一个根类型Any,是所有类的父类 阅读全文 »
scala变量 发表于 2021-04-27 更新于 2023-06-24 分类于 scala 阅读次数: Valine: 本文字数: 553 阅读时长 ≈ 1 分钟 scala变量scala的变量声明方式和java不同,scala声明变量必须对变量进行初始化 123// 声明语法 var|val 变量名[:变量类型] = 变量值// 类型是可以省略的,编译器可以进行类型推导var age: Int = 10 var和val的区别 在声明变量时可以使用var或者val来声明 12345// 类型推断val ans = 8*5// 指定类型val sex:Int = 1var age:Int = 10 var修饰的变量可以改变,val修饰的变量不可改变,相当于java中使用final修饰的变量 val是线程安全的,效率更高 阅读全文 »
HBase读数据过程 发表于 2021-04-27 更新于 2024-03-06 分类于 hbase 阅读次数: Valine: 本文字数: 284 阅读时长 ≈ 1 分钟 HBase读数据过程 Client先访问zookeeper,从meta表读取region的位置,然后读取meta表中的数据,meta中又存储了用户表的region信息 根据namespace、表名和rowkey在meta表中找到对应的region信息 找到这个region对应的regionserver 查找对应的region 先从MemStore找数据,如果没有,再到BlockCache里面读 BlockCache还没有,再到StoreFile上读(为了读取的效率) 如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端
HBase命令 发表于 2021-04-26 更新于 2024-08-07 分类于 hbase 阅读次数: Valine: 本文字数: 5.3k 阅读时长 ≈ 5 分钟 HBase命令建表命令使用create命令来创建一个表 123# create '表名称','列族名称1','列族名称2'...# test是表名,cf为列族名create 'test','cf' 阅读全文 »
HBase部署启动 发表于 2021-04-25 更新于 2024-06-06 分类于 hbase 阅读次数: Valine: 本文字数: 1.5k 阅读时长 ≈ 1 分钟 HBase部署启动 使用的版本为2.2.7 单机模式从简单地开始,先来个单机版的,出现问题也比较好解决,首先配置hbase-env.sh 1234# 确保配置了java环境export JAVA_HOME=/usr/1.8# 如果为false则使用独立的zookeeper,如果为true则使用hbase内置的zookeeper# export HBASE_MANAGES_ZK=false 修改hbase-site.xml配置文件 123456789101112131415<!-- hbase的根目录 --> <property> <name>hbase.rootdir</name> <value>hdfs://localhost:9000/hbase</value> </property> <!-- hbase的zookeeper数据目录 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/usr/local/myself/hbase-2.2.7/zkData</value> </property><!-- hbase集群模式关闭,是否运行在分布式模式下 --> <property> <name>hbase.cluster.distributed</name> <value>false</value> </property> 阅读全文 »