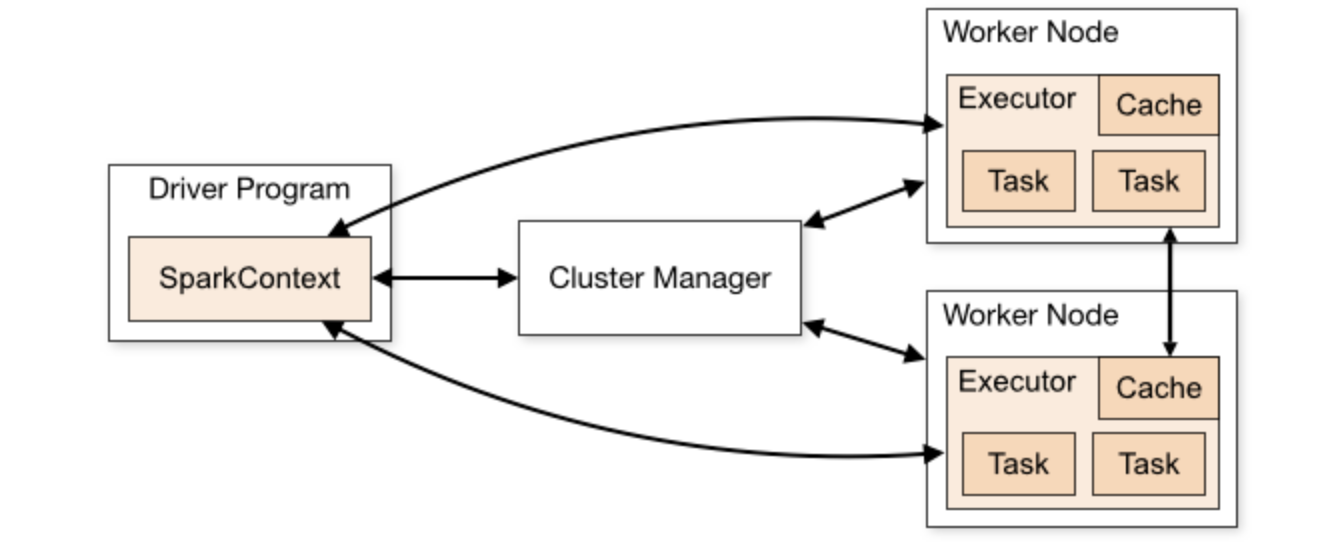
/* Internally, each RDD is characterized by five main properties: * * - A list of partitions * - A function for computing each split * - A list of dependencies on other RDDs * - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) * - Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file) */ // 分区列表,用于执行任务时并行计算 protecteddefgetPartitions: Array[Partition] // 分区计算函数,使用分区函数对每一个分区进行计算 defcompute(split: Partition, context: TaskContext): Iterator[T] // RDD之间的依赖关系,多个计算模型进行组合时,需要建立多个RDD的依赖关系 protecteddefgetDependencies: Seq[Dependency[_]] = deps // 分区器,可以通过设定分区器自定义数据的分区(可选) @transientval partitioner: Option[Partitioner] = None // 首选位置,计算数据时,可根据计算节点的状态选择不同的节点位置来进行计算,可以减少一些不必要的网络传输 protecteddefgetPreferredLocations(split: Partition): Seq[String] = Nil