数据库设计
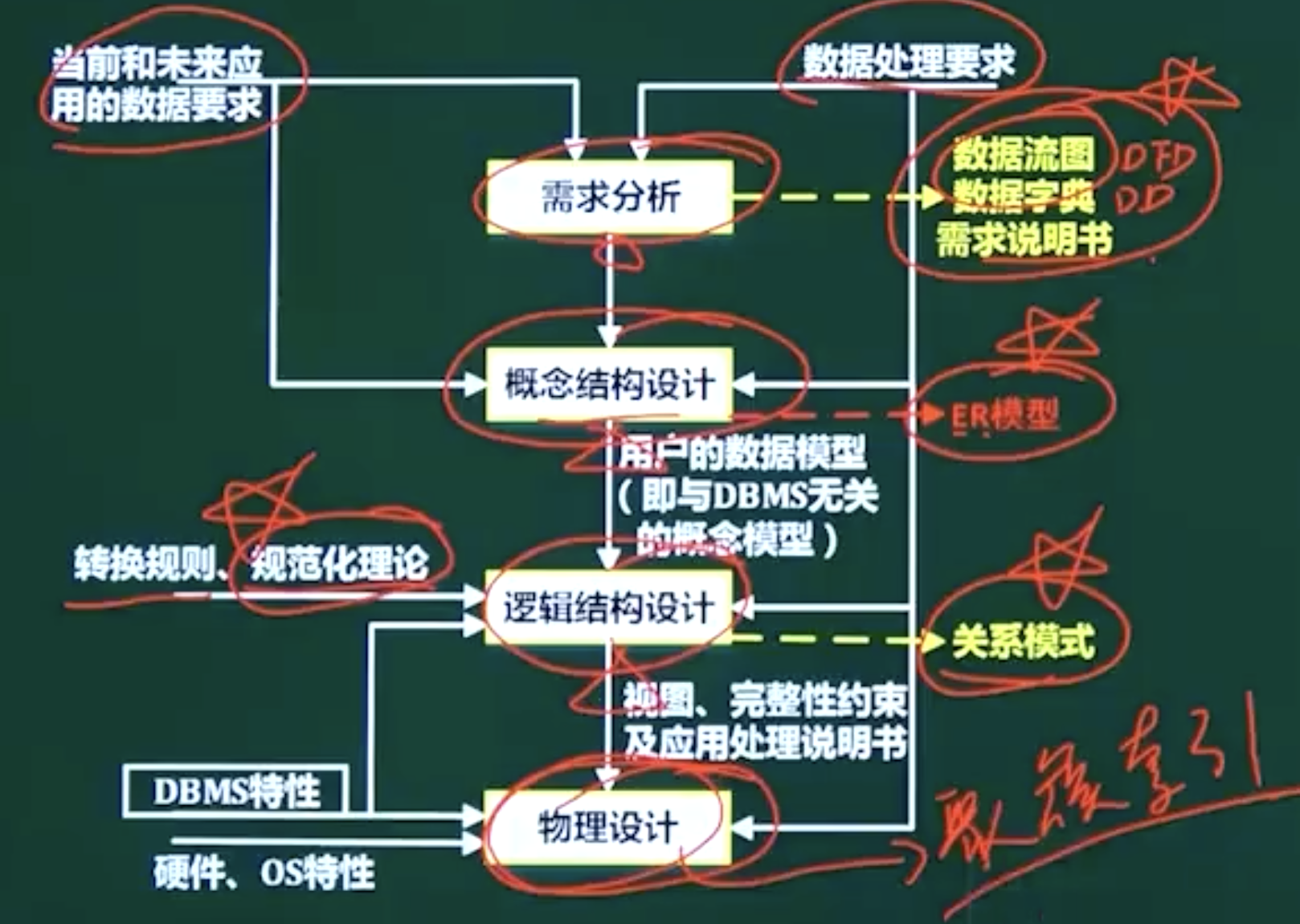
数据库设计分为四个阶段
- 需求分析阶段 了解用户需求确定系统边界,作为概念结构设计的依据,建立需求说明文档、数据字典、数据流图
- 概念设计阶段 对信息分析和定义,采用ER模型
- 逻辑设计阶段 将ER图转换为指定的数据模型、关系模式、确定完整性约束和确定用户视图
- 物理设计阶段 聚簇索引是在物理设计确定的
需求分析
分析用户的需求,包括数据、功能和性能需求。
需求分析阶段建立需求说明文档、数据字典和数据流图,还可以使用判定树、判定表等工具
数据字典
数据字典是各类数据描述的集合,是关于数据库中数据的描述,即元数据,而不是数据本身。包括数据项、数据结构、数据流、数据存储和加工5部分
数据项描述 = {数据项名,数据项含义说明,别名,数据类型,长度,取值范围,取值含义,与其他数据项的逻辑关系}
数据结构描述 = {数据结构名,含义说明,组成:{数据项或数据结构}}
数据流描述 = {数据流名,说明,数据流来源,数据流去向,组成:{数据结构},数据量,存取方式}
数据存储描述 = {数据存储名,说明,编号,流入的数据流,流出的数据流,组成:{数据结构},数据量,存取方式}
加工描述 = {加工名,说明,输入:{数据流},输出:{数据流},处理:{简要说明}}
概念设计
概念结构的设计阶段用数据模型明确地表示用户的数据需求。其反映了用户的现实工作环境,与数据库的具体实现技术无关。(设计E-R模型)
包括抽象数据、设计局部视图、合并取消冲突、修改重构消除冗余
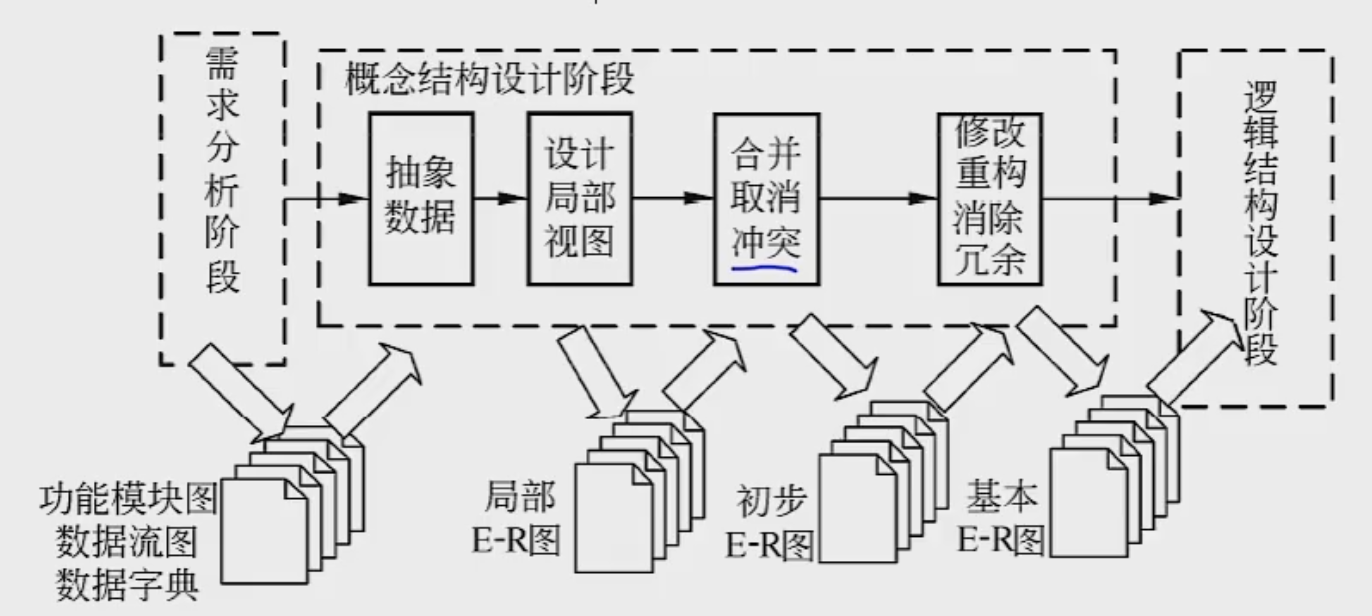
集成的方法有:
- 多个局部E-R图一次集成
- 逐步集成,用累加的方式一次集成两个局部E-R图
集成产生的冲突和解决方式:(冲突是针对于同一对象)
- 属性冲突:同一属性可能会存在于不同的分E-R图,对属性的类型、取值范围和数据单位可能会不一致。
- 命名冲突:相同意义的属性在不同的分E-R图中有不同的含义,包括同名异议和异名同义
- 结构冲突:同一实体在不同的分E-R图中有不同的属性,同一对象在某一分E-R图中被抽象为实体,在另一分E-R图中又被抽象为属性,需要统一
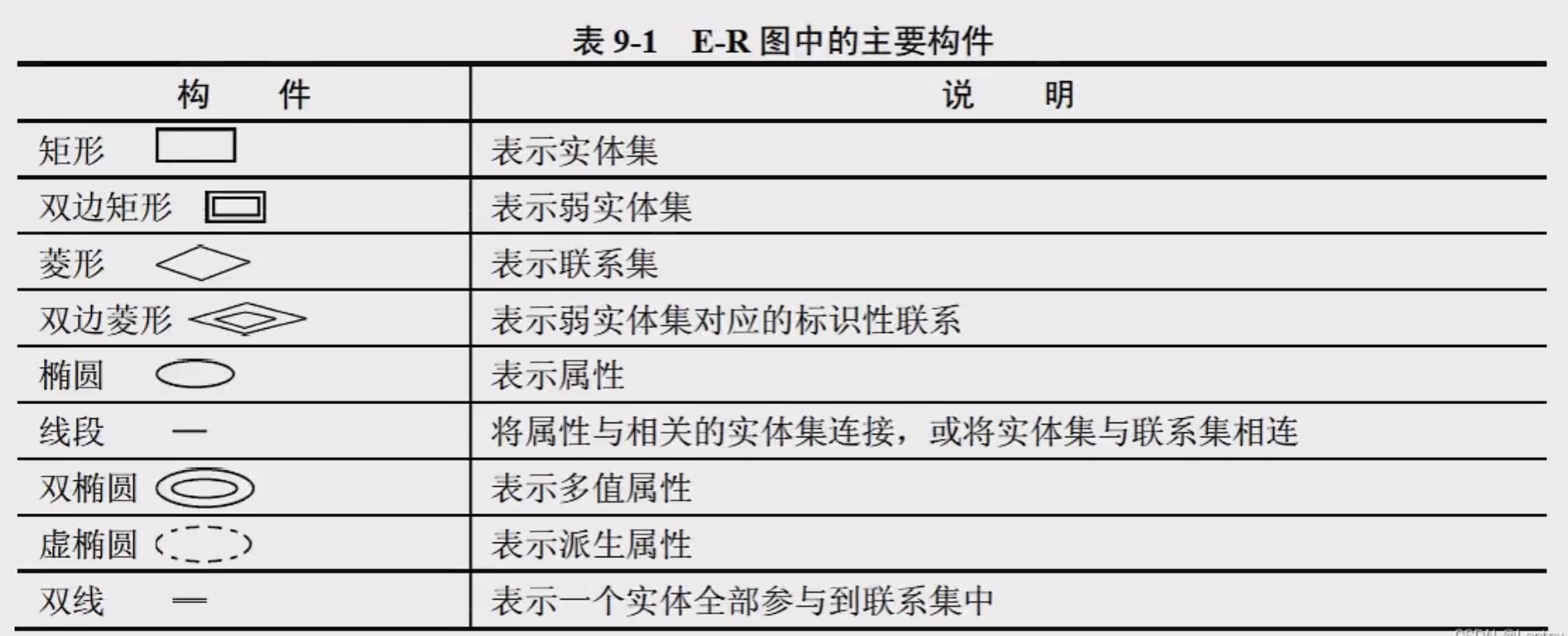
E-R图
E-R图中包括实体、联系(一对一1:1、一对多1:n、多对多m:n)、属性
逻辑设计
根据概念数据模型及软件的数据模型特性,按照一定的转换规则和规范化理论,把概念模型转换为逻辑数据模型,关系规范化是在逻辑设计阶段实现的。对关系模型进一步规范化处理,初始的关系模式并不符合要求,可能会存在数据冗余、更新异常等问题,需要根据范式来对关系模式进行分解。
逻辑结构设计是在概念结构的基础上进行数据模型设计,可以是层次模型、网状模型、关系模型和面向对象模型,对于数据库而言,一般使用的是关系模型。数据模型的三要素是数据结构、数据操作、数据的约束条件。
关系模式就是二维表,数据库表
过程为 转化为数据模型、关系规范化、模式优化、设计用户子模式
完整性约束
- 实体完整性 主键,唯一、非空
- 参照完整性 外键
- 用户自定义完整性约束 条件约束,如非空,范围等
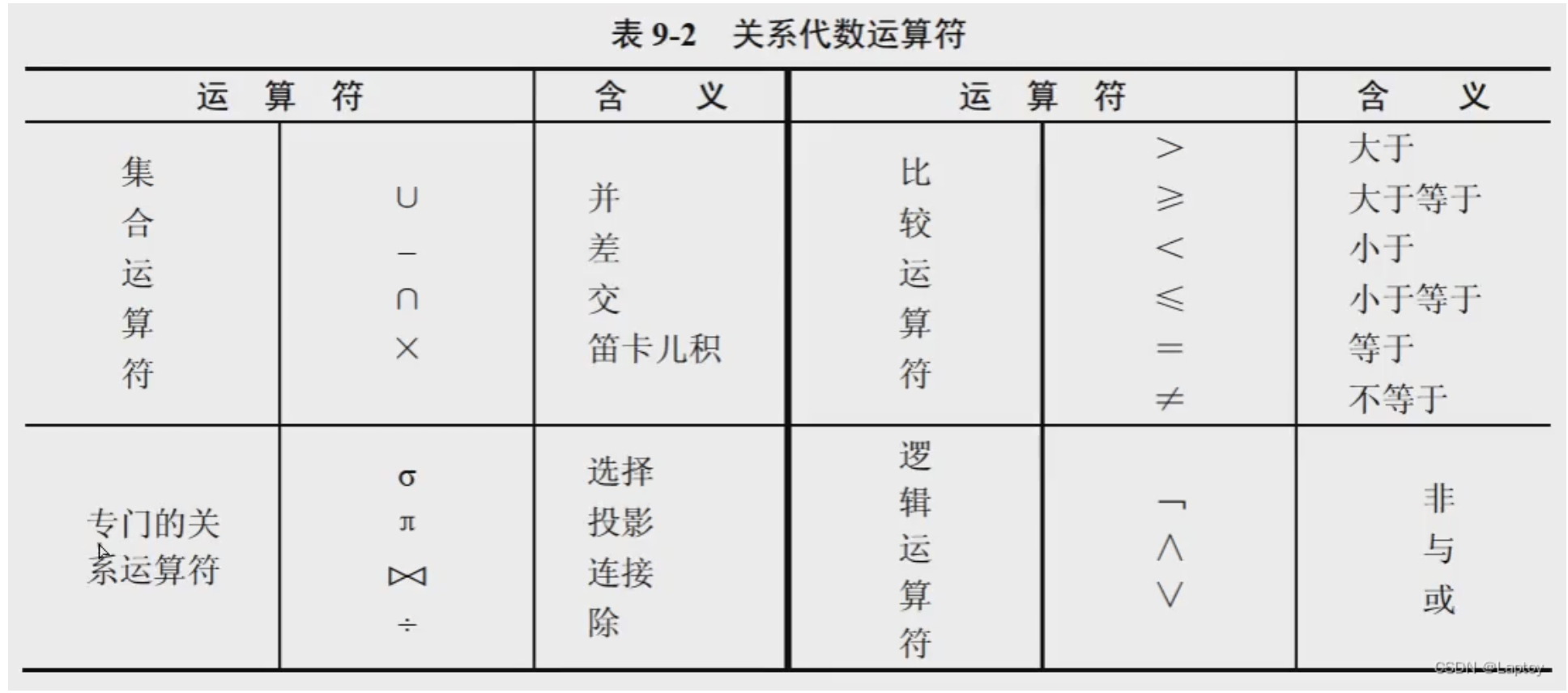
关系代数
模式分解
无损连接
将关系模式分解之后得到的多个关系模式,如果可以通过自然连接得到所有属性则为无损连接。
判断方法:
分解之后的R1、R2进行交集,在分别进行差集,如果交集能推出差集即为无损连接。
1 | 例:关系模式R (A1,A2,A3),函数依赖集F={A1A3->A2,A1A2->A3}。将R分解为p={{A1,A2}, {A1,A3}}。 |
保持函数依赖
将关系模式分解之后得到的多个关系模式,如果可以满足分解的关系模式的关系与分解前的关系一致,则为保持函数依赖(对于冗余函数可以不进行保留)
举例:现有关系模式R
对于ABCE,有关系A->BC、BC->E、E->A
A->BC表示的是A->B且A->C
对于CD,有关系C->D
所以保持函数依赖
物理设计
物理设计为一个确定的逻辑数据模型选择一个最适合应用要求的物理结构的过程。包括确定数据分布、存储结构和访问方式的工作