kafka生产者
kafka使用脚本kafka-console-producer.sh命令发送消息
脚本
1 | if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then |
该脚本调用的是ConsoleProducer类
源码
1 | def main(args: Array[String]): Unit = { |
配置说明
在server.properties中配置kafka的各个属性
acks确认机制,用于配置代理接收到消息后向生产者发送确认信号,以便生产者根据acks进行相应的处理,该机制通过属性request.required.acks设置,0、-1、1三种,默认1
acks=0时,生产者不需要等待代理返回确认消息,而连续发送消息。消息投递速度加快,broker接手之后直接回复ack,但是此时leader没有落盘,如果broker故障就可能丢失数据
acks=1时,生产者需要等待leader副本已成功将消息写入日志文件。降低了数据丢失的可能性,但还是存在,如果在leader成功存储数据后,follower没有来得及同步,此时leader挂掉了,而follower没有进行同步,从ISR中选举出来新的leader也就没有这条数据,数据就会丢失
acks=-1时,leader副本和所有ISR列表中的副本都完成数据存储之后才会向生产者发送确认消息,这种策略保证只要leader副本和follower副本中至少有一个节点存活,数据就不会丢失
batch.num.messages配置,kafka批量向代理发送消息,该配置表示每次批量发送消息的最大消息数,当生产者使用同步模式发送时该配置失效
message.send.max.retries 默认3 重试次数
retry.backoff.ms 默认值100 在生产者每次重试前,生产者会更新主题的MetaData信息,以此来检测新的Leader是否已经选举出来。因为Leader选举需要一定时间,所以此选项指定更新主题的MetaData之前生产者需要等待的时间,单位ms
queue.buffering.max.ms 默认1000 在异步模式下,表示消息被缓存的最长时间,单位ms,当到达该时间后消息将开始批量发送;若在异步模式下同时配置了缓存数据的最大值batch.num.messages,则达到这两个阈值之一都将开始批量发送消息
queue.buffering.max.messages 默认值10000 在异步模式下,在生产者必须被阻塞或者数据必须丢失之前,可以缓存到队列中的未发送的最大消息条数,即初始化消息队列的长度
batch.num.messages 默认值200 在异步模式每次批量发送消息的最大消息数
request.timeout.ms 默认值1500 在需要acks时,生产者等待代理应答超时时间,单位ms 若在该时间范围内还没有收到应答,则会发送错误到客户端
send.buffer.bytes 默认100k Socket发送缓冲区大小
topic.metadata.refresh.interval.ms 默认5min 生产者定时请求更新主题元数据的时间间隔。若设置为0,则在每个消息发送至后都会去请求数据
client.id 默认为console-producer 生产者指定的一个标识字段,在每次请求中包含该字段,用于追踪调用,根据该字段在逻辑上可以确认是哪个应用发出的请求
queue.enqueue.timeout.ms 默认2147483647 该值为0表示当队列没满时直接入队,满了则立即丢弃,负数表示无条件阻塞且不丢弃,正数表示阻塞达到该值时长后抛出QueueFullException异常
生产者命令
kafka-console-producer脚本提供了生产者发布消息调用kafka.tools.ConsoleProducer类
生产者发送消息
1 | # 无key消息 |
参数说明
broker-list 要连接的服务器(必传,kafka_2.12-2.50版本之前使用该参数)
bootstrap-server 要连接的服务器(必传,kafka_2.12-2.50版本之后使用该参数)
topic 接收消息的主题名称(必传)
batch-size 单个批处理中发送的消息数 200(默认值)
compression-codec 压缩编解码器 none、gzip(默认值) snappy、lz4、zstd
max-block-ms 在发送请求期间,生产者将阻止的最长时间 60000(默认值)
max-memory-ytes 生产者用来缓冲等待发送到服务器的总内存 33554432(默认值)
max-partition-memory-bytes 为分区分配的缓冲区大小 16384
message-send-max-retries 最大重试发送次数 3
metadata-expiry-ms 强制更新元数据的时间阈值(ms) 300000
producer-property 将自定义属性传递给生成器的机制 key=value 会覆盖配置文件中的配置
producer.config 生产者配置属性文件(producer-property优先于此配置)
property 自定义消息读取器 key.separator= 分隔符 ignore.error=true|false
request-required-acks 生产者请求的确认方式 0/1(默认)/all
request-timeout-ms 生产者请求的确认超时时间 1500(默认)
retry-backoff-ms 生产者重试前,刷新元数据的等待时间阈值 100(默认)
socket-buffer-size TCP接收缓冲大小 102400(默认)
timeout 消息排队异步等待处理的时间阈值 1000(默认)
sync 同步发送消息
version 显示kafka版本 不需要配合其他参数,显示本地版本
查看消息是否发送使用kafka-run-class脚本,该命令有一个time参数,支持-1(lastest)、-2(esrliest),默认-1
1 | >kafka-run-class kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic kafka-test |
查看信息
kafka生产的消息以二进制的形式存在文件中,kafka提供了查看日志文件的kafka.tools.DumpLogSegments,files是必传参数,可传多个文件,逗号分隔
1 | >kafka-run-class kafka.tools.DumpLogSegments --files ../../logs/kafka-test-1/00000000000000000000.log |
生产者性能工具
kafka提供了一个生产者性能测试脚本kafka-producer-perf-test,可以对生产者进行调优。
脚本
1 | if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then |
命令
脚本调优调用的是org.apache.kafka.tools.ProducerPerformance类
topic参数 指定生产者发送消息的目标主题
num-records 测试时发送消息的总条数
record-size 每条消息的字节数
throughput 限流控制(小于0时不进行限流;参数大于0,当已发送的消息总字节数与当前已执行的时间取整大于该字段时生产者线程会阻塞一段时间,生产者线程被阻塞时,在控制台可以看到输出一行吞吐量统计信息;参数等于0,生产者在发送一次消息之后检测满足阻塞条件时将会一直被阻塞)
producer-props 以键值对的形式指定配置,可同时指定多组配置,多组配置之间以空格隔开
producer.config 加载生产者级别的配置文件
1 | >kafka-producer-perf-test --num-records 1000000 --record-size 1000 --topic kafka-test --throughput 1000000 --producer-props bootstrap.servers=localhost:9092 acks=all |
records sent 测试时发送的消息总数
records/sec 每秒发送的消息数来统计吞吐量
MB/sec 每秒发送的消息大小来统计吞吐量
avg latency 消息处理的平均耗时
max latency 消息处理最大耗时
50th/95th/99th/99.9th 百分比的消息处理耗时
测试数据工具
kafka提供了一个用于生成测试数据的脚本kafka-verifiable-producer.sh,用于向指定主题发送自增整型数字消息
脚本
1 | if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then |
命令
1 | max-message参数用于指定要发送的消息总数 |
kafkaProducer
kafkaProducer是一个用Java语言实现的kafka客户端,实现了Producer接口,用于将消息(ProducerRecord)发送到代理。kafkaProducer是线程安全的,在一个kafka集群中多线程之间共享同一个kafkaProducer实例比创建多个性能好。
kafkaProducer有一个缓存池,用于存储尚未向代理发送的消息,同时一个后台IO线程负责从缓存池读取消息构造请求,将消息发送至代理,producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(partition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)
写入流程
1)producer先从zookeeper的 “/brokers/…/state”节点找到该partition的leader
2)producer将消息发送给该leader
3)leader将消息写入本地log
4)followers从leader pull消息,写入本地log后向leader发送ACK
5)leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit 的offset)并向producer发送ACK
源码解析
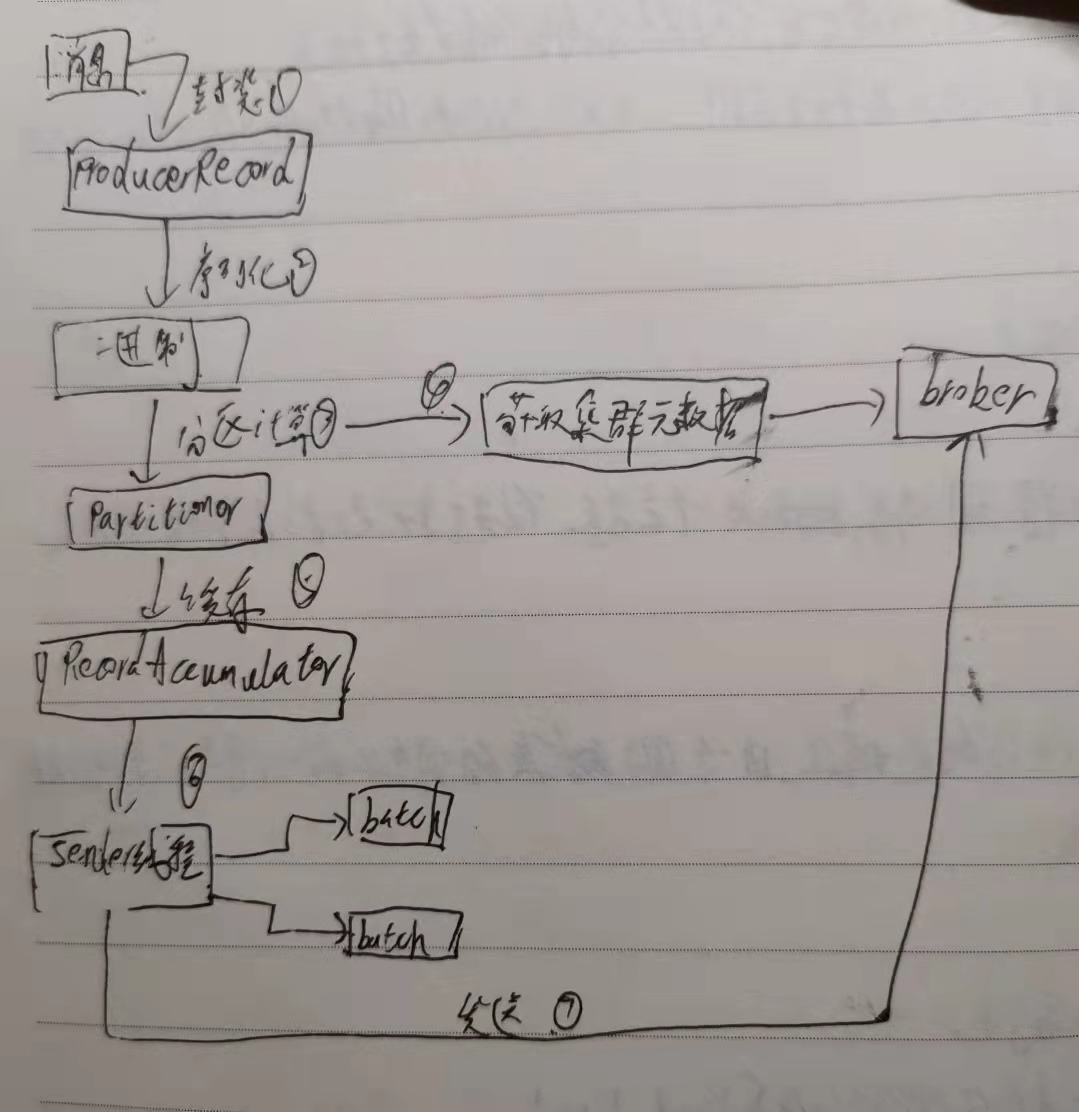
一条消息过来首先会被封装成为一个 ProducerRecord 对象
对象进行序列化
消息序列化完了以后,对消息要进行分区
分区的时候需要获取集群元数据
分好区的消息不是直接被发送到服务端,而是放入了生产者的一个缓存里面(RecordAccumulator)。在这个缓存里面,多条消息会被封装成为一个批次(batch),默认一个批次的大小是 16K(为了减少网络传输)
RecordAccumulator中维护了一个双端队列,消息写入缓存时,追加到双端队列的尾部,Sender读取消息时,从双端队列的头部读取
Sender 线程从缓存里面去获取可以发送的批次
Sender 线程把一个一个批次发送到服务端
实例化
1 | //默认情况下的配置,为了防止篇幅过大,将后面的注释去掉了 |
1 | KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer, Metadata metadata, KafkaClient kafkaClient) { |
send方法分析
1 | public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) { |
doSend方法
1 | private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) { |
waitOnMetadata方法
1 | private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long maxWaitMs) throws InterruptedException { |
RecordAccumulator的append方法
1 | // 变量 |
1 | public RecordAppendResult append(TopicPartition tp, |
tryAppend方法
这里说明一下,在实例化RecordAccumulator的时候会创建一个BufferPool,BufferPool维护了一个Deque
1 | private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, |
ProducerBatch的tryAppend方法
1 | public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) { |
sender线程
sender是在KafkaProducer实例化的时候启动的,
1 | public void run() { |
1 | void run(long now) { |
1 | private long sendProducerData(long now) { |
1 | private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) { |