Yarn工作机制
分为五个实体
- 客户端:提交MapReduce作业
- YARN资源管理器:负责协调集群上计算资源的分配
- YARN节点管理器:负责启动和监视集群中机器上的计算容器
- MRAppMaster:负责协调运行MapReduce作业的任务。和MapReduce任务在容器中运行,这些容器由资源管理器分配并由节点管理器进行管理
- HDFS:用来与其他实体间共享作业文件
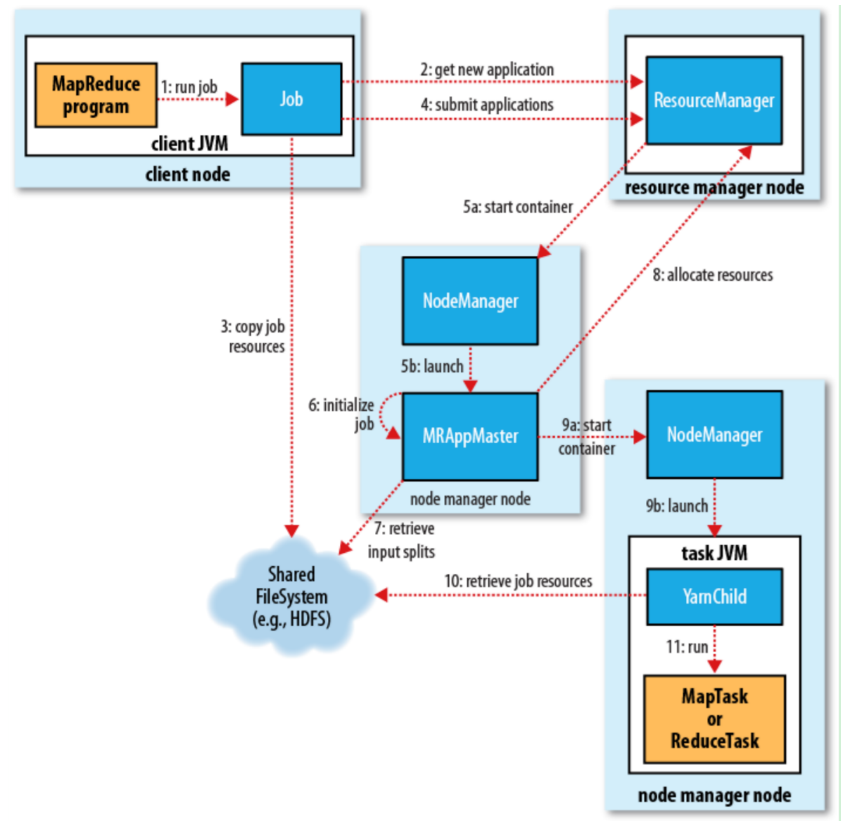
MapReduce运行job,MapReduce程序提交到客户端所在的节点,job.waitForCompletion创建YarnRunner。会创建JobSubmitter实例,并调用submitJobInternal方法
向ResourceManager申请一个Application,ResourceManager会生成一个Application的资源提交路径hdfs://../staging以及application_id
将job运行所需要的资源提交到该路径下的application_id文件中(资源包含Job.split、Job.xml、执行的jar程序)
调用资源管理器的submitApplication方法提交作业
-5a 资源管理器收到submitApplication()消息后,将请求传递给YARN调度器(scheduler),调度器会分配一个容器
-5b 资源管理器在节点管理器的管理下在容器中启动application master的进程(application master是一个java应用程序,主类是MRAppMaster)
application master对作业进行初始化(是通过创建多个簿记对象以保持对作业进度的跟踪来完成的)
接收来自HDFS的输入分片,对每一个分片创建一个map任务对象以及由
mapreduce.job.reduces指定的多个reduce任务对象(此时会分配任务id)application master为作业中的所有map任务和reduce任务向资源管理器请求容器
-9a 容器分配后,application master通过与节点管理器通信来启动容器
-9b 该任务由YarnChild来运行
运行任务前,将任务需要的资源本地化,包括作业的配置、JAR文件和所有来自分布式缓存的文件
运行map任务或reduce任务