MapReduce简介
为什么要有MapReduce
MapReduce也是来源于Google中的MapReduce,是为了解决PageRank(搜索排名)问题,由于网页过多,进行计算网页权重时需要大量的计算,MapReduce将大任务拆分成小任务,然后再进行汇总
原理
MapReduce是Hadoop中的计算部分,将计算分为了两个阶段:Map阶段和Reduce阶段
Map阶段
Map阶段任务拆分并行处理输入数据
- Map阶段将任务拆分为MapTask,并行运行,相互不会影响
map阶段实现Mapper接口,并实现接口的map方法,map方法中的value值存储的是HDFS文件中的一行,key为该行的首字符相对于文件首地址的偏移量
map任务将其输出写入到本地硬盘,而非HDFS。由于map的输出是中间结果,该中间结果由reduce任务处理后才产生最终输出结果,一旦作业完成,map的输出结果就可以删除。如果运行map任务的节点在将map中间结果传送给reduce任务之前失败,Hadoop将在另一个节点重新运行这个map任务再次构建map中间结果
Reduce阶段
Reduce阶段对Map结果进行汇总
- Reduce阶段的ReduceTask也互不相干,数据来源是MapTask
reduce阶段需要实现Reducer接口,并实现接口的reduce方法,reduce方法中的key对应map中输出的key,values则对应了map阶段中该key输出的value集合
MapReduce组成
一个MapReduce程序是由三个进程实例组成的
- MrAppMaster 负责整个程序的过程调度及状态协调
- MapTask 负责Map阶段的数据处理流程
- ReduceTask 负责Reduce阶段的数据处理流程
流程
![MapReduce流程]()
示例
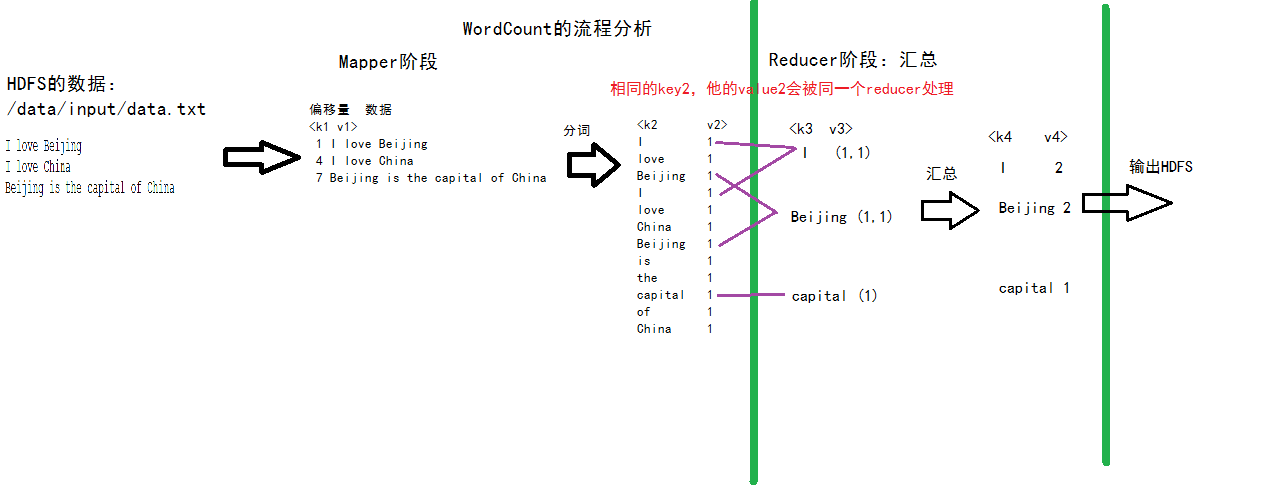
过程分析
![WordCount的流程分析]()
使用MapReduce来实现一个wordCount
提供了五个可编程组件,分别是InputFormat、Mapper、Partitioner、Reducer和OutputFormat
注意新API是在org.apache.hadoop.mapreduce包下
依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>com.zhanghe.study.mapreduce.wordcount.WordCountDriver</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
|
代码展示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
public class WordCountMapper extends Mapper<LongWritable, Text, Text,IntWritable> {
Text text = new Text();
IntWritable intWritable = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for(String word : words){
text.set(word);
context.write(text,intWritable);
}
}
}
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable value = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable intWritable : values){
sum+=intWritable.get();
}
value.set(sum);
context.write(key,value);
}
}
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}
|
优缺点
优点
- 易于编程,通过实现一些接口即可完成一个分布式计算
- 易扩展,计算能力不足时,加机器即可
- 高容错性,某个机器挂了,可以自动将任务转移到其他机器
- 海量数据的离线处理
缺点
- 不擅长实时计算
- 不擅长流式计算
- 不擅长有向图的计算